
Tackle Semantic Search
Tackle Semantic Search
I noticed that many DS folk(including myself) were tackling challenges in the search space. Sharing some of my notes on it. Assumes you know the basic SBERT architecture. Do check it out!

How to do Semantic Vector-based Search?
This is not a research paper, so it doesn’t contain any lengthy math/explanations. No intro either; as it’s only meant for those who have a background in BERT, Transformers and SBERT. I suggest you understand them before starting here. This is basically just a highly condensed survey paper. Just pasting some of my own notes here. I call this a
TL;DR:)
This TL;DR covers a niche within search that deals with semantic understanding since SBERT [ goodbye BM25 :) ]. The text embeddings thus obtained can be used for dense-vector based retrieval(Document vector A can be used to find document B, C and D that are semantically closest to it). So why not use the cross-encoder? Because it doesn’t scale well with millions of documents. Not discussing averaged word embeddings here either, although they are worth trying out if it suits your domain (lightweight too).
What are we discussing exactly?
Want to get an embedding for XYZ text belonging to a general domain? Use USE. Or try mean pooling of BERT (BERT family of models so to say) embeddings. Or try the
[CLS]token embedding (only reliable if trained on a downstream task). You’ll have to experiment to see which one works best.What is a “general domain”? These are domains like pop culture, weather, trivia, politics, and so on. In simple words, mainly the Wikipedia text and Common Corpus (stuff that BERT, USE, etc. are generally trained on).
Want to go domain-specific? Just do the same as above, right? Wrong. You need to finetune the model to your domain. Unless you’re lucky enough to have good domain-specific models that is… (looking at you, BioBERT) This entire
TL;DRdiscusses this particular case in detail…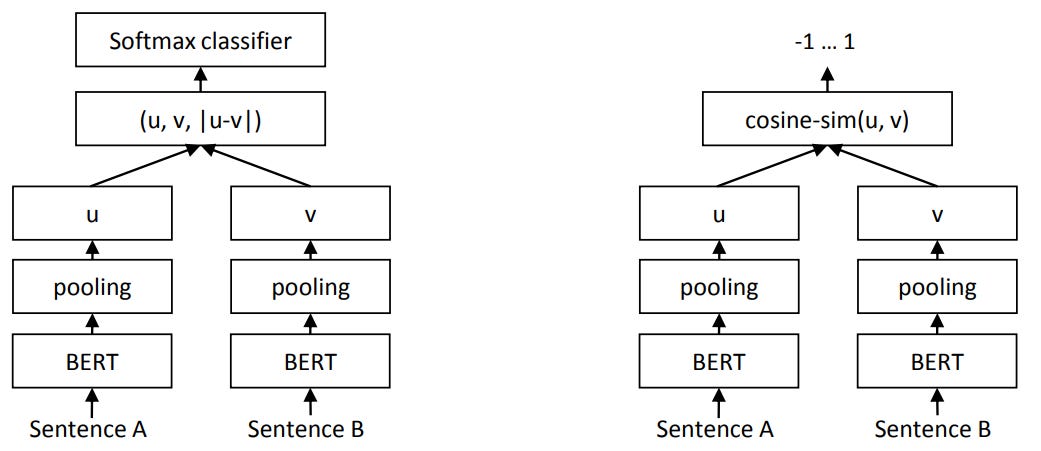
Refresher on SBERT’s Siamese architecture from SBERT paper

A. Supervised version
Here, we train a Siamese model to bring together(or separate) encodings based on some special metric. The SBERT paper is the godfather for this particular scenario. Need labeled data though :(
Pros: Robust. Can be optimized for a specific online metric. Relatively more tried and tested.
Cons: Labeled data required. More DS side decision-making required. More experimentation.
The whole discussion on this (Supervised domain-tuning) is a bit lengthy. Hence, I’ve mentioned it at the end. Scroll down to see it.
B. Unsupervised(Self-Supervised) version
Trained only on texts. Don’t need labeled data.
Pros: Simpler, no fancy optimization metric required, few other technical challenges get removed. No labeled data required.
Cons: Can’t be directly trained on optimizing a specific metric (like maximization of BUY orders)
What are some recent techniques? Contrastive Tension, TSDAE (basically SDAE on Transformers)
Contrastive tension/CT is a mind-blowingly simple idea. Two independent Transformer models trained on maximizing the vector dot product for identical (yes, identical) sentences and minimizing it for non-identical ones. There is no weight sharing between the two Transformers, so you can choose which one you want :). CT is SOTA (nerd word for “best”) on encoding-based STS. But not too good on other tasks though (as per the author).
SimCSE, another architecture, is very similar to CT. The only noticeable difference being the use of dropout masks to introduce noise/data augmentation. Put simply, the positive pairs take the exact same sentence as input, with the only difference being dropout masks.
TSDAE seems like the ideal unsupervised approach for sentence encoding tuning for now. Unlike CT, it has SOTA on various benchmarks, not just STS. SDAE (on which it is based) was a popular paper too, it is simple to understand: just denoising LSTM autoencoders on sequences. TSDAE just extends that idea to Transformers. Why did I never think of that…
Ok. So how do I domain-tune BERT embeddings in a Supervised fashion?
Simple. You need a dataset either of the STS or NLI format (read the GLUE paper to understand these formats in detail). Just to save you the time:
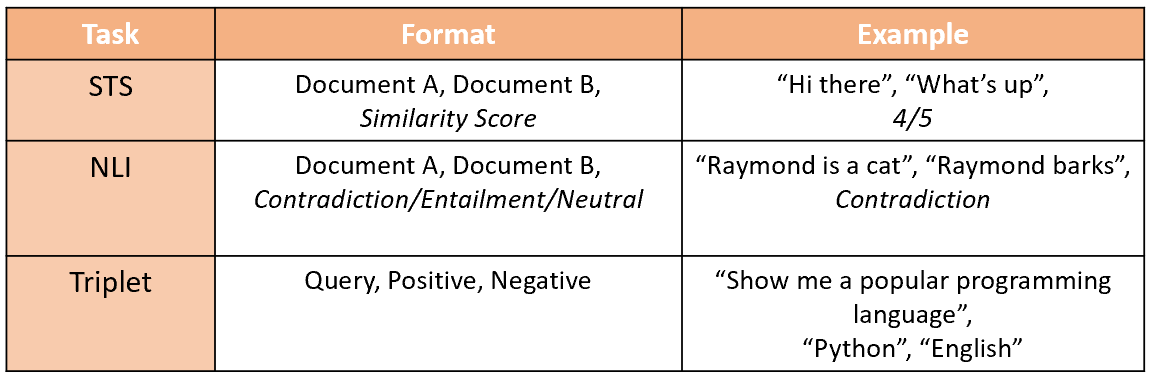
Some other possible datasets:
<query> <document> <relevant/not relevant><query> <document> <relevance score>Tonnes of other combinations…
Generally, Triplets can be artificially mined from a dataset of pairs of similar documents. We can do that based on Hard, SemiHard, Negative sampling discussed by SBERT and Oliver Mondroit here and here. Simple gist of the two links:
Loss(for Triplet data generation):
L=max(d(a,p)−d(a,n)+margin,0)
(“a” is the anchor", “p”/“n” positives/negatives, “margin” is a hyperparameter)Easy Triplets: Choose all examples where loss is zero
Hard Triplets: Choose examples where
d(a,n)<d(a,p). Negative sample embedding closer to the anchor than positive.Semi-Hard Triplets: Choose examples where
d(a,p) < d(a,n) < d(a,p)+margin.
These are NOT “Hard Triplets” per se, but the examples where loss is still positive.
Once you have the dataset, an SBERT-like model can be trained using losses like:
Cosine Similarity Loss (self-explanatory)
Contrastive Loss: similar to 1., but instead we focus on minimizing the dot product. Also tends to be two different tower networks, without any weight sharing. The goal here is to drive similar documents closer and dissimilar ones farther away.
Multi Negative Ranking Loss: Useful if you only have positive pairs of query and document. Basically makes a (mostly correct) assumption that all out-of-order examples would be wrong (aka negatives) and all in order examples are positives. Worth checking out.
Triplet Loss (if you use triplets):
loss = max(||anchor - positive|| - ||anchor - negative|| + margin, 0).
Simple Logic. Positives should be closer to anchor than the negatives.
Generally, from the above list, 1. and 3. would form a good starting point as they should be able to cater to most use cases.
One important point to note; minimizing dot product generally leads to a preference for longer result documents while minimizing cosine similarity leads to shorter ones (from the Contrastive Tension paper if I remember correctly). You can try the SBERT framework (GitHub link here) to try some things I have discussed.
One final thing, Retrieve and Re-Rank
A very simple technique. Put simply, we know the following:
Cross-Encoders generally beat vector-based techniques
Cross-Encoders are infeasible at a large scale
Vector-based techniques are scalable
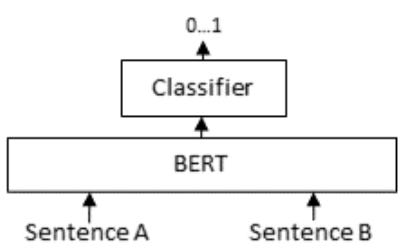
Want best of the both worlds? Try this popular technique:
Fetch Top N(say 1000) relevant documents using a lightweight algorithm like vector search discussed above (or even BM25). It’s okay to let in a few not-so-great results. We are targeting high recall here.
Re-rank these N documents so that the most relevant results come on top. Re-ranking can be done using Cross-encoders this time because we have a smaller number of documents.
This could possibly help you get very good results while still keeping infrastructure costs in check.
Good luck and have fun doing search!
Very neat and crisp explanation!
I loved how succinct this is. I had tried the same BM25+SBERT method which works well.
Another method I can think of is getting all embeddings by passing them through SBERT and using Annoy/Faiss.
I am also maintaining a repo for info rel to Semantic Search. https://github.com/Agrover112/awesome-semantic-search
Would be great to have you contributing this article or any papers to our repo.